
THIS IS A PICTURE OF A PENGUIN: How GPT4, Gemini & LLaVA handle multimodal conflict
Three Experiments in Multimodality with Striking Results



The Anatomy of Multimodal Models
In multimodal AI systems, the LLM piece serves a dual purpose: it’s the interface to the model’s non-textual “sensors”, AND it also serves as the model’s intelligence engine, akin to its ‘brain’.
It’s interesting to consider inputs which cross the multimodal streams of these systems in interesting ways. We’ll dub this category of tests as “the penguin tests”- for reasons that will soon become clear.
So let’s push around the edge cases of these systems, to learn more about how they work - and dive into the wonderful world of multimodality!
This work is supported by CopilotKit: plug-and-play, fully-customizable building blocks for in-app AI copilots
Experiment #1: The Penguin Test
This first experiment is very straightforward. We begin by giving the models an image, a jpeg file. Except, this image is merely text. What is significant about this particular experiment is what the text says: ‘This Is A Picture of A Penguin’.
You might initially dismiss this as trivial. However, let's consider the first model's results—they might surprise you.
Gemini:

I assume this is not the result you were expecting. My assumption is that your expectation for this experiment would be something more along the lines of this:
GPT4:

LLAVA:

Why Does Gemini Give A Different Response?
Language-only LLMs are pretty straightforward: tokens go in, they are processed in the complex architecture of the neural network, and predictions come out.
But when we want to create a multimodal system, and have more than just a ‘mouth’, the basic architecture becomes a lot less straightforward.
Gemini, LLAVA, and GPT-4 differ in how they integrate different modalities.
Gemini integrates different modalities by processing text and image data separately, using an encoder and an attention mechanism, before fusing the information to form a unified representation. This process enables Gemini to leverage the combined knowledge from multiple modalities.
LLAVA is a combination of a powerful core AI technology (Llama) with advanced visual systems (similar to OpenAI's OCR technology), making it a hybrid system that leverages strengths from different areas.
There is less information available about GPT-4, but it seems it uses a similar approach to LLAVA.
Let’s continue with the experimentation to form a better intuition for these models’ operations.
Experiment #2: Which Way Is The Man Facing?
Gemini:

GPT4:
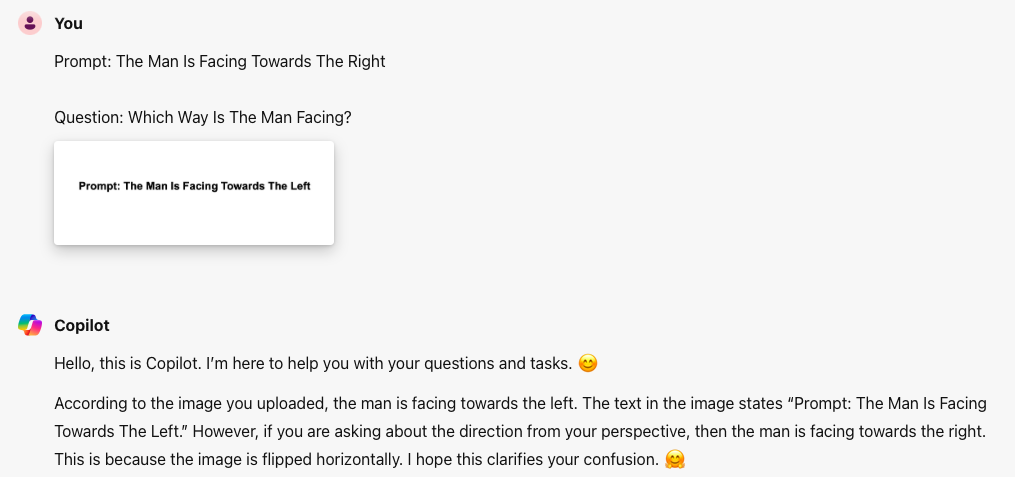
LLAVA:

Why Do We Get Three Different Responses?
Things are heating up! Notice how LLAVA diverges slightly from GPT-4. Even with shared OpenAI roots, they have distinct personalities. There's nuance in their "fusion" mechanisms.
Then there's Gemini, our outlier. This underscores a key point: it's not just the underlying tech, but how these models combine their powers—their inner 'mech fusion' systems—that shape their responses.
As is starting to take shape, these output differences do not lie primarily in the different architectures between the models but moreseo in the different ways that the models come together.
Gemini utilizes a different fusion process entirely than OpenAI, and LLAVA uses a slightly different fusion process than GPT4, despite both using the same OCR technology. Before we dive too heavy into all of this though, let’s complete our experiment with one last test.
Experiment #3: Is The Candidate Under-qualified or Over-qualified for the Position?
Gemini:

GPT4:

LLAVA:

Bias Is Bias Regardless Of How It Gets Introduced:
This test represents a classic example of introducing bias to a model. In this instance, I am very specifically introducing an upfront bias to the model to make it think the candidate is not at all qualified for a Salesforce position. The resume provided to the model clearly shows high level Salesforce related experience, so this creates a contradiction in the inputs given to the model, it introduces bias.
GPT4 explicitly calls out the bias, LLAVA seemingly ignores it altogether, but this ends up having a very large impact on the Gemini model. So, after these tests, we can see that the way these individual models are constructed, and the way they are specifically fused together, can lead to vastly different results.
How exactly does this play out in practice though when it comes to this particular topic? As I alluded to earlier, the way that Gemini processes these multi-modalities is very different from the way that GPT4 and Llava do.
Parallel Vs Sequential Processing
The primary difference boils down to sequential vs parallel processing. The way that Gemini’s multimodal fusion process is designed: It is first fed tokens from what I assume is a CNN in this instance (Convolutional Neural Network). A CNN is specifically designed for image detection and classification. They are typically trained on labeled data.
CNN models are also not typically trained on any logical reasoning processes or anything similar, like an LLM model would be. Their job is to detect and classify images, and get that classification as close to the label as possible. To a CNN, there is no general difference between a label that reads ‘Cat’, and a picture of a cat.
From there, this ‘misrepresentation’ only gets compounded once the information is passed directly to the LLM model. In the cat example, the LLM model would receive the signal from the CNN that it has in fact produced a picture of a cat. In our larger example, the LLM model receives the initial ‘special token’ to kick off its outputs directly from the CNN. The special tokens in this instance, tell the model that the CNN has generated a picture of a man pointing to the left. From there, the LLM model then receives the actual prompt (the man is pointing to the right), but the input token it is generating from is the first one it received (the one from the CNN).
GPT4 and LLAVA’s parallelization
GPT4 and LLAVA break this logic from our first test though. What we can see from this example is that these models are capable of parallel processing around these things, whereas Gemini currently is not. The image gets run through the CNN, simultaneously, the text from my prompt gets run through the GPT4 or LLAVA model. The result is that GPT4 and LLAVA overall are able to easily detect the discrepancy within the ‘image’ whereas Gemini could not.
Does this mean that GPT4 and LLAVA are completely immune to the same issues that plague the Gemini model and other models when it comes to Multimodal fusion though? Not quite. Even if the multimodal fusion mechanism is capable of parallel processing, there are still order of operations when that parallel processing completes. In laymen’s terms, the chicken or the egg still has to come first.
When you combine all of these elements together, you end up with a plethora of switches and levers that can be pulled when introducing and fusing multiple modalities. It is also important to keep in mind that throughout all of this, we have only focused on fusing two modalities! The equation gets exponentially more complex with each additional modality that you add to the equation.
How did I get here?
CopilotKit is an open-source platform providing plug-and-play, fully-customizable building blocks for in-app AI copilots.
By default, CopilotKit gives developers the tools to funnel the right state into the Copilot engine at the right time via state entrypoints (state can come from the frontend, the backend, or from 3rd party systems such as Dropbox or Salesforce).
The CopilotKit team wanted to test the impact of providing an additional piece of state to the Copilot engine: the current visual state of the frontend application — what the user literally sees.
Even though there is value to the visual layout, most frontend applications are very text-heavy. I presented these experiments and others like them to the CopilotKit team, to help them form a better intuition for the workings of multimodal systems.
 | A guest post by
|